|
|
SPAMIA - výskumno-vývojový projekt
Slovanetu pre nové antispamové algoritmy. (projekt základného výskumu podľa zákona č. 185/2009 Z. z. o stimuloch pre výskum a vývoj) |
|||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
|
|
Algoritmus
Vznik nového algoritmuRiešiteľský tím SPAMIA sa už v začiatkoch projektu zameral na hľadanie odlišných spôsobov nazerania na e-mailovú komunikáciu ako je tomu u iných rozšírených metód. Jednou z jeho vízií bolo pokúsiť sa aplikovať na rozpoznávanie nevyžiadanej pošty pokročilé štatistické metódy, ktoré sa ukázali byť účinné aj v iných podobných oblastiach. Výsledky analýz veľkého množstva vzoriek elektronickej pošty v úvodných etapách projektu podporili perspektívu tohto smerovania a výskumný tím sa zameral práve týmto smerom. Teoretický návrh nového algoritmu filtrovania spamu prináša uspokojivé výsledky už v predbežných pracovných testoch, porovnateľné s niektorými v praxi bežne používanými nástrojmi. Riešiteľský tím ho v súčasnosti rozvíja a hľadá cesty jeho optimalizácie a zvyšovania účinnosti. V ďalších etapách výskumu sa bude navrhnutý algoritmus overovať v reálnom prostredí poštového systému internetového poskytovateľa. Princíp algoritmu SPAMIANa rozdiel od väčšiny bežne používaných metód filtrovania spamu, založených najmä na textovej analýze, je algoritmus navrhnutý tímom projektu SPAMIA založený na číselnom charakterizovaní e-mailu pomocou takzvaných kvantitatívnych profilov a ich spracovaní pokročilými štatistickými metódami. Ako príklad možno uviesť riadkový profil, ktorý si všíma a pre klasifikáciu používa počty znakov textu v jednotlivých riadkoch, čiže si všíma akoby „vizuálny tvar“ textu e-mailu. Ďalším je znakový profil, ktorý je v základnom tvare vlastne histogramom početností jednotlivých znakov e-mailu. Skupina rekurenčných profilov je, zjednodušene povedané, založená na kvantifikovaní mier opakovania sa určitých štruktúr v texte e-mailu. Pri úvodných analýzach spamu v slovenskom prostredí sa práve závislosť na jazyku ukázala byť slabým miestom text-miningových algoritmov. Navrhovaný prístup nevyužíva lexikálnu ani syntaktickú analýzu a je teda nezávislý od jazyka, v ktorom sú e-maily napísané. Súčasťou návrhu algoritmu je aj efektívny mechanizmus jeho učenia sa, čo je dôležité pre minimalizáciu výkonových nárokov v reálnom nasadení. Inovatívnosť riešenia spočíva vo vhodnom využití kvantitatívnych profilov v spojení s ďalšími štatistickými metódami, a to spôsobom, ktorý na klasifikáciu e-mailov doteraz pravdepodobne ešte nikto nepoužil. Výhodou tejto metódy je tiež možnosť kombinovať ju s inými bežne používanými riešeniami postavenými na analýzach textu či blacklistoch a tým dosiahnuť ešte vyššiu celkovú účinnosť rozpoznávania nevyžiadanej pošty. PodrobnejšieBežne používané metódy filtrovania spamuVo všeobecnosti sa v prístupoch k filtrovaniu spamu využívajú dva základné druhy informácií – externé (napr. blacklisty a whitelisty) a interné – získateľné výlučne z e-mailu (z jeho hlavičiek s technologickými informáciami a najmä z jeho samotného textu). Výskum projektu SPAMIA sa zameriava na interné informácie. Väčšina v súčasnosti používaných metód filtrácie využíva najmä textovú a lexikálnu analýzu s využitím postupov a algoritmov text-miningu. Analýzami informácií uvedených vo verejne dostupných empirických štúdiách o výkonnosti niektorých antispamových riešení dospel riešiteľský tím SPAMIA k záveru, že efektívnosť algoritmov založených na textovej analýze e-mailov má svoje hranice a principiálne obmedzenia. Navyše akékoľvek ďalšie zlepšovanie ich efektívnosti by bolo neprimerane výpočtovo a kapacitne náročné. Ďalšími závažnými nedostatkami štandardných textových algoritmov na filtrovanie spamu, a dôvodmi prečo je potrebné hľadať alternatívne prístupy, sú:
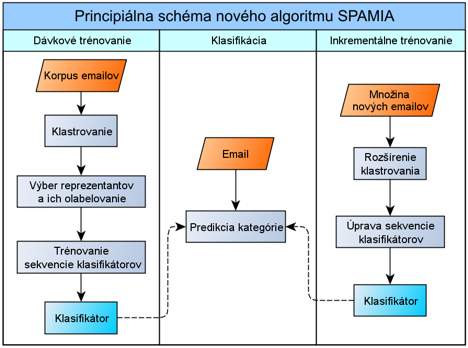
Princíp algoritmu SPAMIA – podrobnejšieZ hľadiska spracovania spočíva nový prístup projektu SPAMIA k filtrovaniu a kategorizácii e-mailov v dvoch inováciách. Prvou z nich je reprezentácia e-mailov pomocou tzv. kvantitatívnych profilov (vektora číselných údajov vopred zvolenej dimenzie). Druhou inováciou je adaptívne klastrovanie korpusu e-mailov využiteľné jednak pre podporu efektívneho labelovania a relabelovania korpusu, ale hlavne pre získanie informácie aj z nelabelovaných e-mailov. Tento fakt zaraďuje návrh filtrovania do triedy semi-supervised algoritmov. Okrem týchto dvoch inovácií algoritmus využíva sekvenčné adaptívne klasifikovanie a inkrementálne trénovanie. Celkový pohľad na algoritmus podáva nasledovný diagram:
Obr.: Koncept nového algoritmu je založený na kombinácii viacerých postupov matematickej štatistiky a nosnými piliermi nového algoritmu su najmä kvantitatívne profily, adaptívne klastrovanie a sekvenčné klasifikovanie. Medzi významné črty algoritmu, vyplývajúce z reprezentácie e-mailov kvantitatívnymi profilmi, patria hlavne:
Vďaka adaptívnemu klastrovaniu algoritmus získava nasledovné vlastnosti:
Predbežné meranie efektívnostiTím SPAMIA vykonával v priebehu navrhovania nového algoritmu predbežné testovanie úspešnosti základných kvantitatívnych profilov – riadkového a znakového. Efektívnosť profilov bola porovnaná s úspešnosťou voľne dostupných a používaných nástrojov SpamAssassin (heuristické pravidlá) a Bogofilter (naivný Bayesov filter), merania sa uskutočnili na jednom privátnom a dvoch verejných korpusoch (množín e-mailov obsahujúcich spam aj ham). Úspešnosť bola vyhodnocovaná pomocou dvoch základných mier úspešnosti – na základe podielu zle klasifikovaných hamov (false positive rate) a podielu zle klasifikovaných spamov (false negative rate). Prvotné empirické výsledky dokazujú, že jednoduché a ľahko získateľné riadkové a znakové profily sú schopné dosahovať prinajmenšom porovnateľnú výkonnosť ako nástroje SpamAssassin s niekoľkými stovkami heuristických pravidiel a Bogofilter založený na naivnom Bayesovom filtri. Dá sa oprávnene predpokladať, že ďalšie navrhované kvantitatívne profily dokážu efektívnosť ešte zvýšiť. Ďalšie pokračovanie projektuV ďalších etapách výskumu sa riešiteľský tím projektu SPAMIA zaoberá návrhom simulačných scenárov na verifikáciu účinnosti skúmaných algoritmov, výskumom účinnosti vyvinutých algoritmov v reálnom prostredí elektronickej komunikácie, a výstupom projektu bude vypracovanie a zverejnenie sumarizujúcej štúdie. SPAMIA je projekt základného výskumu, čo znamená, že jeho výsledkom sú predovšetkým verejne publikované a kýmkoľvek ďalej použiteľné vedecké poznatky, ktoré sa tak stávajú príspevkom do celosvetového znalostného dedičstva. Tie výsledky základného výskumu, ktoré majú potenciál konkrétneho praktického využitia, sa následne spravidla stávajú predmetom aplikovaného výskumu, resp. komerčného využitia. Výsledky a štúdie projektu SPAMIA sú prezentované predovšetkým na tejto projektovej web stránke (http://spamia.slovanet.sk), na vedeckých portáloch, v odborných periodikách a na konferenciách. Dokončenie projektu SPAMIA je plánované na júl 2013 a Slovanet v ňom bude pokračovať ďalším vlastným 5-ročným výskumom a vývojom, ku ktorému sa v rámci projektu zaviazal. Výsledky výskumu plánuje Slovanet využiť aj vo vlastnej praxi vo vhodnej kombinácii s ďalšími nástrojmi pre znižovanie podielu nevyžiadanej pošty, čiže v prospech používateľov internetu. Viac informáciíPodrobnejšie informácie o výsledkoch a stave projektu získajte na stránke Štúdie, odporúčame najmä štúdiu výsledkov 3. etapy projektu. Dosiahnuté výsledky (publikácia, patent, ochrana priemyselného vlastníctva, iná aktivita) vznikli v rámci riešenia projektu „Výskum efektivity algoritmov pre inteligentné rozpoznávanie nevyžiadanej elektronickej komunikácie, návrh teoretických modelov nových algoritmov a posúdenie ich účinnosti“ (SPAMIA), ktorý je podporovaný Ministerstvom školstva, vedy, výskumu a športu SR v rámci poskytnutých stimulov pre výskum a vývoj zo štátneho rozpočtu v zmysle zákona č. 185/2009 Z.z. o stimuloch pre výskum a vývoj… |
|
|||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||
|
© 2010-2013 Slovanet, a.s. Projekt SPAMIA je podporovaný Ministerstvom školstva, vedy, výskumu a športu SR. |
||||||||||||||||||||||||||||||
|
|
||||||||||||||||||||||||||||||